There is a growing body of academic research looking at all aspects of emoji usage 😍🌴😀👍
By Alexander Robertson, PhD Candidate, University of Edinburgh
Emoji and society
If you have a mobile phone made in the last eight years, or if you've used social media, you're likely familiar with emoji. The colorful icons, first available in Japan in the 1990s, are ubiquitous and an increasingly common part of our online lives. They have all but replaced emoticons, their punctuation-based precursors, though kaomoji (more detailed emoticons, originating in Japan) such as ᕕ( ᐛ )ᕗ still enjoy popularity in some corners of the internet. Perhaps the most compelling example of emoji popularity was the "face with tears of joy" emoji 😂 being selected as the Oxford Dictionaries Word of the Year in 2015 - a fact you will find in the introduction of many academic papers on the topic.
New additions to the emoji inventory generally make the news and there have been many campaigns to have specific emoji added in order to highlight issues or causes. A church in Finland wants a forgiveness emoji, a children's charity wants a period emoji to overcome stigma surrounding menstruation, and emoji showing interracial couples were added following a campaign by Tinder. And where specific emoji are not available, charities like Jo's Cervical Cancer Trust are using them to raise awareness of the importance of smear tests and encourage public dialogue on the issue.
Emoji and research
Alongside popular interest in emoji is a growing body of academic research looking at all aspects of emoji usage. Some is from a computational perspective, some takes a sociological or linguistic approach.
Effective word embeddings for emoji
Pre-trained word embeddings, used in all sorts of natural language tasks to represent text, don't usually include emoji because emoji are usually removed from text as part of pre-processing. But it turns out that you can use the canonical text descriptions of emoji (e.g. 🤷 is described as "woman shrugging") to train these embeddings very quickly, rather than training on large corpora as is usually required. See emoji2vec: Learning Emoji Representations from their Description for full details.
Predicting emoji from text
A central task in NLP is language modelling. Given a sequence of words, the model predicts the most likely word to come next. In the emoji setting, the aim is to predict the most probable emoji. This is usually posed as a classification task, where the input text is labelled with one of a subset of the most commonly used emoji. This restriction is motivated due to the relative rarity of emoji compared to words (traditional language models will generally never predict emoji), and classification using all 3000+ emoji would have a similar problem when dealing with rare/uncommon emoji. For a recent attempt to address the issue of predicting rare emoji, see Interpretable Emoji Prediction via Label-Wise Attention LSTMs.
Semantics of emoji
What do individual emoji mean, broadly speaking? Do they have positive or negative associations? Do they provoke happy or sad emotions? Work in this area has examined human judgements for emoji and has shown that most are positive, with people generally agreeing on the emotional association of each emoji. These findings are consistent between speakers of different human languages, too. A handy visual presentation of these results can be found at the Emoji Sentiment Ranking website.
Interpretation of emoji
If you've always used an Android or an Apple phone, then you might not be aware that the same emoji can be rendered differently on different platforms. Check out the Emojipedia entry for "grimacing face" for an example of just how different they can be. Studies of the emoji which are not universally agreed upon showed that this disagreement is even greater when the emoji are sent and received on different platforms. For full details, see "Blissfully Happy" or "Ready to Fight": Varying Interpretations of Emoji.
Emoji and self-identity
Working with Professor Sharon Goldwater and Dr Walid Magdy at the University of Edinburgh, our research looks at how emoji are used on Twitter, how the emoji we use change based on who we are, on what we are talking about and who we are talking to. A key component of this work is emoji skin tone modifiers. Introduced in 2015, these allow us to apply a skin tone to certain emoji and make them appear more human.

Examples of emoji with and without skin tones applied.
The addition of these skin tones generated a lot of online discussion. This is one of the handy things about doing emoji research - you can just go and see what wild claims are being made in the comments of the Daily Mail website and turn them into research questions. 🙃 So, would anyone bother to use them, since there are already so many emoji? Would white people be willing to use them, or at least those who aren't white supremacists? Would people use them to indulge in "digital blackface" or as part of racist abuse online?
Starting with a corpus of around one billion tweets made in 2017, I found that around 14% had at least one emoji and 7% contained an emoji with a skin tone applied to it. So they are definitely being used! And as the image below shows, the most common skin tone used is actually the white one.

Proportion of emoji skin tones by region.
However, we needed more data in order to answer the question about abusive usage. Since abusive usage is most likely to involve a person using an emoji that does not match their own skin tone, we need to know the skin tone of the person behind the tweet. This is an annotation task - we show the user's Twitter profile photo to three annotators, ask them to determine the skin tone and keep only those users on whom all annotators agree.
With this ground truth demographic information about Twitter users, we can look at "inapposite tweets": instances where light-skinned people used dark-skinned emoji and vice versa. We can then perform sentiment analysis on these tweets and see if they are negative.
The graphic below shows the proportion of these tweets made by each group, arranged by sentiment. Neutral tweets are not shown, as they far outnumber the rest. Negative tweets are rare, especially when we consider them as a proportional of all tweets. In fact, the majority of non-neutral tweets are positive and manual inspection of the negative tweets did not reveal the predicted racial abuse. It seems that if people are going to be racist on Twitter, they don't need emoji to do it - they've got old-fashioned language for that.
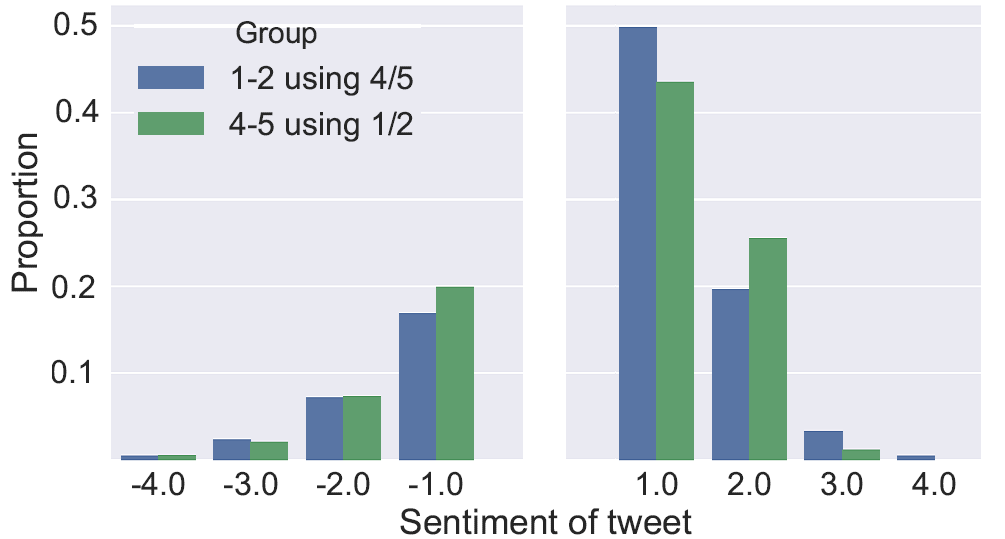
Sentiment analysis of inapposite emoji tone usage.
Another benefit of having a dataset with annotated users is that we could examine individual populations. The distribution of skin tones shown above is really only looking at which appear most often and could be skewed by the fact that there are simply more users with lighter skin tones. What is more interesting is whether people use skin tones that reflect their identity. To do this, we took the annotated users, grouped them by skin tone and determined their most-used emoji skin tone. The results, below, shows that people do use a skin tone which matches or is close to their actual skin tone.

Tone usage per group.
The exceptions are users with skin tone 2, who mostly use emoji skin tone 1, and users with skin tone 5, who mostly use skin tone 4. Why is that? Let's look at the five skin tones applied to the "person" emoji on the Apple platform.

Examples of tones applied to one emoji.
Two things should stand out. First, the hair color of skin tone 2 is blonde! So users with this skin tone may be dissuaded from using it if they don't have blonde hair. Second, the distribution of the skin tones from lightest to darkest does not appear to be smooth - the difference between tones 4/5 is more apparent than that of any other two adjacent tones. Plotting these tones (as they appear on different platforms) in a three dimensional color space highlights how different the darkest tone is.

Distribution of tones in HSV space.
Users may have this darkest skin tone in real life, but the way emoji are designed is quite simplistic - nothing is done to preserve fine detail and therefore these emoji lose a lot of of their characteristics when a skin tone is applied.
Despite these design issues, though, emoji skin tone modifiers are especially popular with people of color on Twitter, who are more likely to use them at all than white Twitter users and also use them more often if they do use them in the first place. These modifiers were introduced by the Unicode Consortium because "people all over the world want to have emoji that reflect more human diversity, especially for skin tone" and they appear to have achieved that goal.
You can find the full paper, which was presented at ICWSM, on arXiv.org.
Working with Twitter data
If you're interested in working with Twitter data, one of the easiest ways to do so is with the Tweepy package for Python, which not only simplifies authentication but also dealing with rate limits. Automatic handling of how fast/often you can access Twitter data saves you from having to write your own code and helps avoid all sorts of annoying bugs and errors.
Alternatively, there are existing datasets you could work with. Check out this list on Github to get started. For even more academic datasets, take a look at the Inter-university Consortium for Political and Social Research, hosted by the University of Michigan.
Annotating data can be time-consuming, so I used crowdsourcing to do this. At the time of the research, I used Figure Eight but they no longer offer academic pricing. However, I can recommend Prolific which makes it easy to find participants for annotation and experiments online.
About
Alexander Robertson is in the second year of a PhD at the Centre for Doctoral Training in Data Science at the University of Edinburgh. His research combines computational methods and experimental psycholinguistics, to answer questions about how people use and perceive emoji on social media.