Image tagging in SAGE Journals - part one
By James Siddle
Cloud Vision APIs are powerful web services that apply machine learning to tag objects in images, as well as identifying faces, supporting image filtering, extracting text, and providing custom image tagging. At SAGE, we recently asked the question how could Cloud Vision APIs be applied to support scholarly publishing? For example, can they be used for new products or product features, to improve the editorial workflow, or to otherwise enhance SAGE operations or quality of life?

In the first part of this two-part blog series, I explore the outcome of asking that question.
First, I'll briefly review Cloud Vision APIs, and describe a tagging experiment we tried at SAGE. This is followed by a discussion of observations, lessons learned, and some potential use cases in scholarly publishing.
In part two, I'll focus on data analysis use cases, and present an interesting visualization of image tags and how they are related through co-occurrence relationships.
Background - what we did
We extracted approximately 3200 images from SAGE journals, using a pseudo-random extraction technique to ensure a reasonable spread of image types and topics to support our initial analysis.
The images were sent for tagging in two different services, the Google Vision API and Clarifai - using Clarifai's "general" model. There are other Cloud Vision APIs available, and this blog post by Guarav Oberoi does a great job of summarising the top providers. You might also want to the amusing article "Chihuahua or Muffin?" for more API comparison and discussion.
We used the Guarav's freely-available (and very useful) Cloudy Vision image processing tool to process the SAGE images, and to generate an easy to understand web page of the results. We then manually reviewed this to get a sense for how the APIs coped with SAGE journal images.
Observations - what did we learn?
Processing images is cheap. We estimated a sub $10,000 bill from both Google and Clarifai to process the entire SAGE image collection. Images took around 2.5 seconds each which could be a problem for large image collections, though this can likely be improved substantially through batching or bulk data transfer into the cloud.
Cloud Vision APIs do better on photos and distinctive images. A cursory inspection of results showed us that the APIs perform best with photographs. We saw much better performance on distinct photographic subjects such as medical or mechanical engineering photographs, compared to images of tables or charts.

Image tagged as "jack-up rig" by Google Vision API
DOI: 10.1155/2013/105072 in Advances in Mechanical Engineering is licensed under CC BY 3.0
This isn't hugely surprising, as these services originated from processing very large volumes of images on the internet, e.g. for filtering or moderation purposes. Clarifai does support other models for recognizing clothing, food, or detection of specific photographic themes, but sadly none of these seem especially applicable to scholarly publishing.
The APIs use proxy tags for tables and charts. We noticed a consistent theme in the tags returned, especially with tables – the models almost seem to have a layperson's understanding of the topic in these cases. I imagined a friendly builder called Bert holding the image at arm's length and saying "Whaddya reckon Fred? Looks like some sort of calendar or planner to me".
In other words, images of tables and diagrams are often tagged with 'proxy' labels such as "text", "font", "calendar", and "journal". These could in theory be used to classify the images, especially in combination. However, there are likely to be more direct and effective ways to classify the images as tables, than deriving a classification second-hand.
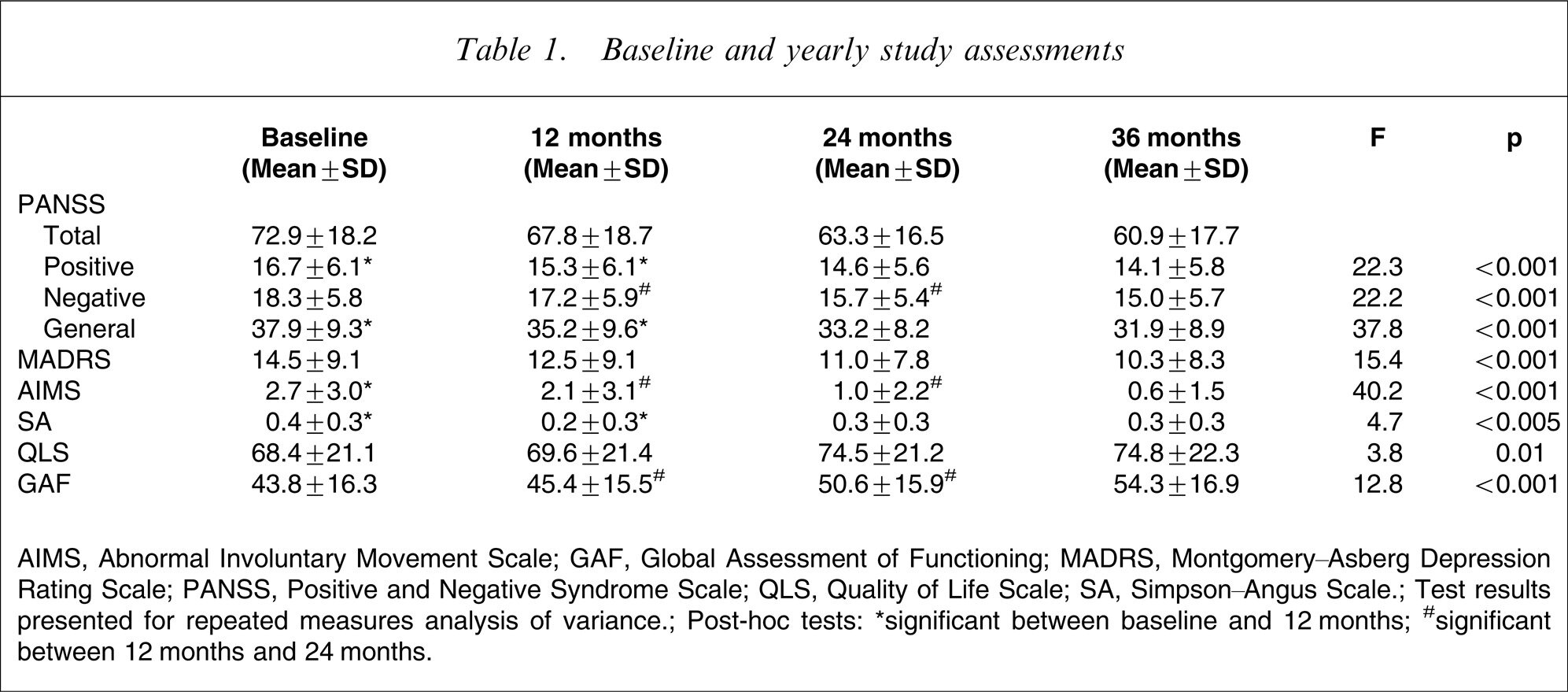
Image tagged by Clarifai, returning: monthly (.99), schedule (.98) , text (.98),
time (.98), business (.97) , daily occurrence (.96)
DOI: 10.1080/00048670701689410 by Jayashri Kulkarni et al in Australian & New Zealand Journal of Psychiatry
It's easy to start anthropomorphizing AI – see above.
There's noise, especially in the tags. We found that tags returned from Cloud Vision APIs are quite noisy, even when taking returned confidence scores into account. This is unfortunate as it undermined our confidence in the Cloud Vision tagging capabilities and restricts potential use cases. Anecdotally speaking, the APIs seemed to return incorrect but closely related tags on many images.
Many other features can be extracted along with image tags. Google for example, extracts facial features and expressions, text fragments and blocks (using Optical Character Recognition), safe search filter classifications (including recognising medical images), landmarks, and company logos. Other APIs have similar features, and as a rule are designed with extensibility in mind so it's fair to expect other interesting capabilities in the future.

Image sent to Google for text extraction, with perfect results except for a single open square bracket which was recognized as a 1. This table includes many interesting terms such as insomnia, nicotine, mental disorder
DOI: 10.1080/00048670701392809 by David Olivier et al in Australian & New Zealand Journal of Psychiatry
These capabilities hint at many possible use cases—some of which are discussed towards the end of this article.
You can train your own models, for example using the Clarifai API. We can't comment directly on the effectiveness of this approach, but it certainly opens up some interesting options. Similarly, start up lobe.ai offer an exciting glimpse into the future of AI as a service, by providing a toolbox for building your own deep learning models.
Finally we learned that not all AI is Artificial. CloudSight offer a hybrid human-AI approach as discovered by Guarav Oberoi in the aforementioned blog post - though CloudSight aren't at pains to point out this fact.
We ran a small experiment with CloudSight, sending an information-rich table of data about botanical extracts. The description returned was the title of the table, that is "Antifungal activity of crude Hypericum extracts".
Unfortunately, the human-in-the-loop managed to introduce a typo and responded with Hpyericum, presumably because of the pressure to meet expected an API-response time. Given the lack of information about what a reasonable response should look like, the actual response is understandable (barring the typo), though it does suggest that more useful, higher quality responses will require greater specialization from both pure AI and hybrid systems, and as a result greater cost.
In a follow-up experiment, we sent following image to CloudSight. In this case, the human-in-the-loop must have gone visibly pale as the image is particularly intimidating and densely packed with textual information. The response was simply "white background with text overlay", which could simply be the response of an underlying machine learning model. It's reasonable to assume that the human involved felt unable to improve on the default response, within the timeframe of the API call.

Cloud Vision APIs with a human-in-the-loop may perform better on everyday objects such as cats and dogs, but this improvement is unlikely to extend to specialized domains or complex data without incurring a much higher cost.
DOI: 10.1177/0394632017750997 in International Journal of Immunopathology and Pharmacology is licensed under CC By-NC 4.0
Scholarly Publishing Use Cases
The use case that immediately pops to mind when considering image tagging for scholarly publishing is in accessibility. There is the potential for tagging very large image collections and providing the resulting tags to vision impaired users, for example. The main challenge here will be ensuring tag quality and relevance, which from an initial review may be acceptable but only for photographs.
Another obvious use case is in filtering medical or surgical images. The Google safe search results were generally good at detecting medical images, which could allow publishers to open their image collections for new use cases, e.g. for article preview or indexing purposes.
The tags could also be used for image search, but with the same caveats around photographs vs tables, graphs etc. In other words, searching for specific objects in images in scholarly collections is feasible but some selection criteria will be necessary to avoid unwanted noise from non-photographic images.
Another compelling use case is to enable searching across text extracted from images. A large proportion of the images from SAGE journals were of text-rich tables, and it would be straightforward to extract the text from these tables using Google's Cloud Vision API. The resulting text can be cleaned up to remove common words and numbers, then the result can be indexed and made searchable – this could make previously inaccessible knowledge available to researchers.
Finally, there may be some Data Analysis use cases, for example through co-occurrence networks - this topic is explored further in part two of this blog series.
About
"Half Product Manager, half Software Engineer, with a sprinkling of Data Scientist, James is an independent IT consultant based on London. He works with various companies in the London technology sector, and has a particular interest in scientific research workflows, life science research, and scholarly publishing. He also has a blog called The Variable Tree where he writes about data, from mining and integration, to analysis and vizualization."